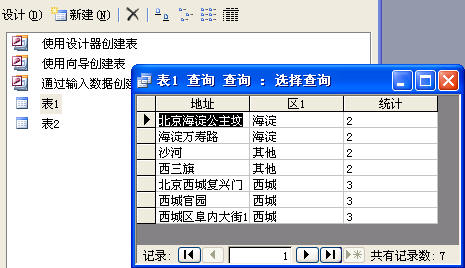
建第一个查询,名为“表1查询”,其Sql语句如下:
SELECT 表1.地址, (Select 区 From 表2 Where InStr([地址], [区])>0) AS 区划, IIf([区划] Is Null,"其他",[区划]) AS 区, DCount("区","表1查询","区='" & [区] & "'") AS 统计
FROM 表1;
再建第二个查询其Sql语句如下:
SELECT 表1查询.区, 表1查询.统计
FROM 表1查询
GROUP BY 表1查询.区, 表1查询.统计
ORDER BY 表1查询.区;
电子表后效果如下图:
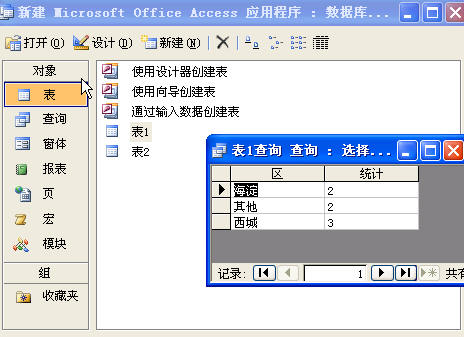
修正一下我在6楼的方法如下:
建第一个查询名为“表1查询”Sql语句如下:
SELECT 表1.地址, (Select 区 From 表2 Where InStr([地址], [区])>0) AS 区划, IIf([区划] Is Null,"其他",[区划]) AS 区
FROM 表1;
建第二个查询名随意,Sql语句如下:
SELECT 表1查询.区, Count(表1查询.区) AS 统计
FROM 表1查询
GROUP BY 表1查询.区
ORDER BY 表1查询.区;
这样速度会更快。
最后回复1楼:
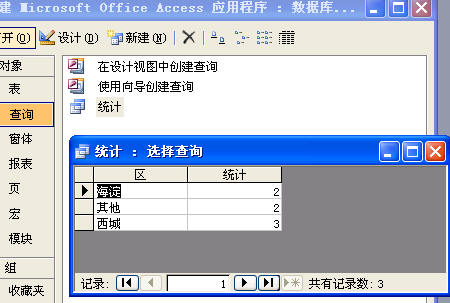
给你一个最终的样库实例,可一步查询实现所要效果:
 点击下载此附件
点击下载此附件
查询效果如下图示:
8楼的效果就是我想要的,感谢koutx,太高了!有点看不懂:
SELECT t1.区, Count(t1.区) AS 统计
FROM [SELECT 表1.地址, (Select 区 From 表2 Where InStr([地址], [区])>0) AS 区划, IIf([区划] Is Null,"其他",[区划]) AS 区 FROM 表1]. AS t1
GROUP BY t1.区
ORDER BY t1.区
弱弱滴问一句,AS t1前为什么必须有个".",我删掉后就出错了。还有,能解释一下这个查询执行的顺序吗?
呵呵,如果严格地讲,用like或InStr提取也是有局限的,也有不遂人愿的地方,但愿你的库里的实际记录不会遇到这种情况:怎么说呢?打个比方吧,有个笑话是:老师要小学生用“如果”造句,他造的是“苹果不如果子酱好吃”,你说这是用“如果”造句吗?同理,对于“西城"区而言,如果有个“山西城东杂货铺”,你看看它绝对属于“西城”区,呵呵,不过,这是多话了,先这么干吧。
说实话,如果系新建数据库,我相信谁也不会采取这种表结构。在表2中加一"区ID"主键,表1中加一ID外键对应,即严密还省却了在表1地址中录入有关区的字词、及随后的逐多处理麻烦。估计楼主是要处理已有的库表或是Excel表等内的数据。如果确实象楼上所说的乌龙数据太多,那可就麻烦唠。
至于楼主在9楼的问题,可如下解释:
[SELECT 表1.地址, (Select 区 From 表2 Where InStr([地址], [区])>0) AS 区划, IIf([区划] Is Null,"其他",[区划]) AS 区 FROM 表1]. AS t1
当然是先执行[]中的语句了,并把它当作一个查询(或者是表)起个别名叫t1吧。
将骨架表示如下就容易明白了:
SELECT t1.区, Count(t1.区) AS 统计 FROM t1 GROUP BY t1.区 ORDER BY t1.区;
楼主该散分了吧?哈哈
谢谢各位!不好意思,昨天没上网,再次感谢koutx!
dengshaobin思维很严谨,提醒了我,但是我的数据是上海的地址,不大会出现那种情况
谢谢楼主的分,又有钱花了。
总记录:14篇 页次:1/1 9 1 :